DeepSeek V4 Preview Released
On April 24, Chinese AI company DeepSeek announced the release of the preview version of its new model series, DeepSeek-V4, which is now open source. The model claims to lead in three dimensions: agent capabilities, world knowledge, and reasoning performance within the domestic and open-source fields.
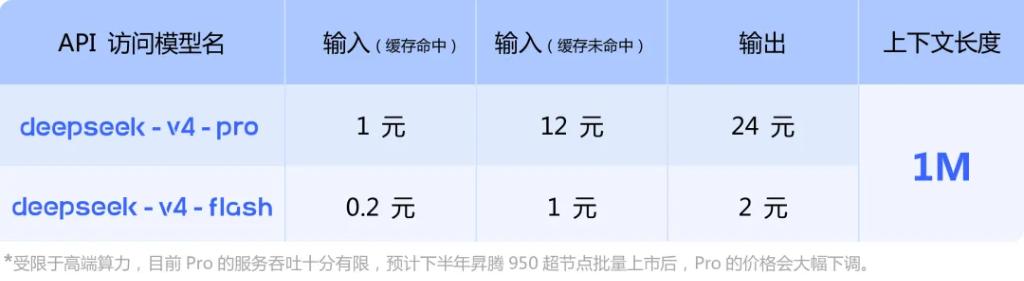
DeepSeek-V4 is available in two versions, Pro and Flash, both supporting a super long context of 1 million tokens and significantly reducing computational and memory requirements.

API services are also launched, allowing developers to call the model by changing the parameters to deepseek-v4-pro or deepseek-v4-flash. The interface is compatible with OpenAI ChatCompletions and Anthropic standards.
DeepSeek also disclosed that due to limitations in high-end computing supply, the Pro version currently has very limited service throughput. It is expected that prices for the Pro version will significantly decrease later this year with the mass release of Huawei’s Ascend 950 super nodes.
Notably, Ascend CANN will live stream the debut of DeepSeek V4 on the Ascend platform at 4 PM.
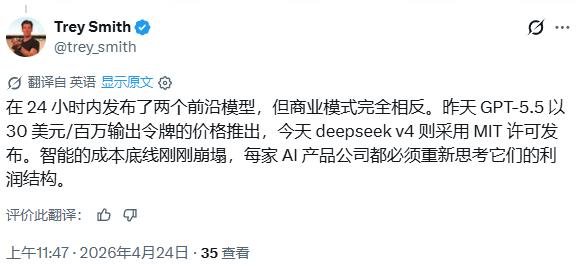
This release coincides almost exactly with OpenAI’s launch of GPT-5.5 the previous day, with starkly contrasting pricing strategies. Some netizens pointed out:
GPT-5.5 launched yesterday at a price of $30 per million output tokens, while DeepSeek V4 was released today under the MIT license, marking a significant drop in AI intelligence costs that forces every AI product company to reassess its profit structure.
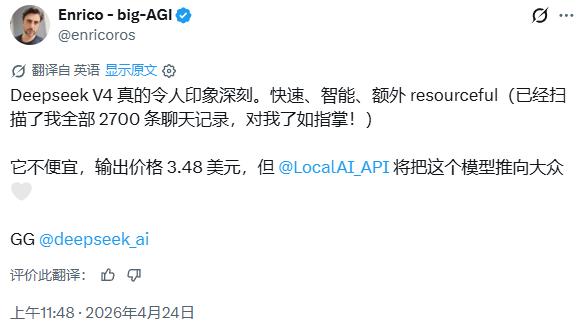
User Enrico commented that DeepSeek V4 is “really impressive, fast, and intelligent,” although he believes the output price of $3.48 per million tokens is “not cheap,” but noted that LocalAI will help promote the model to a broader user base.
DeepSeek-V4-Pro: Performance Comparable to Top Closed-Source Models
DeepSeek-V4-Pro is the flagship version of this release, positioned to match the performance of top closed-source models.
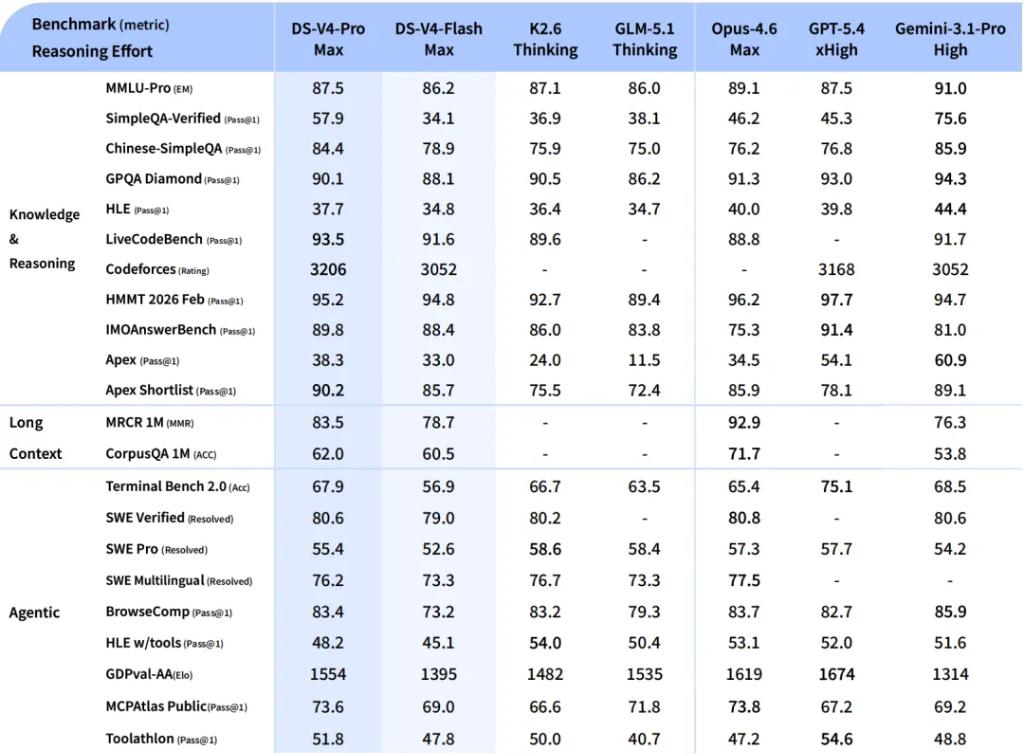
In terms of reasoning performance, V4-Pro claims to surpass all currently published open-source models in mathematical, STEM, and competitive coding assessments, achieving results comparable to the world’s top closed-source models.
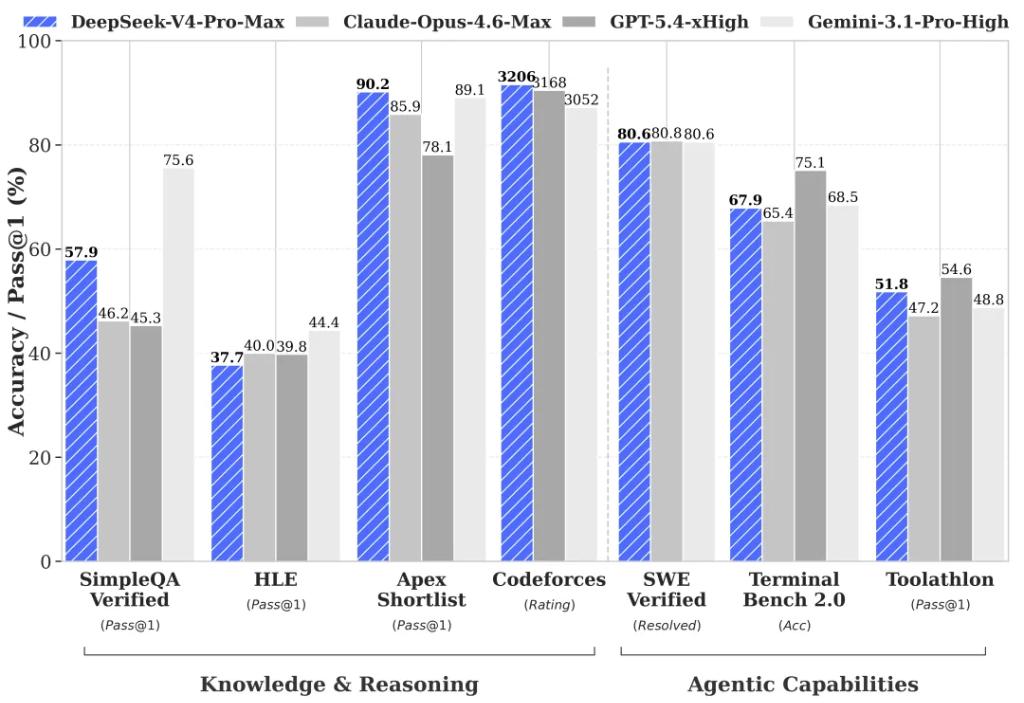
In world knowledge assessments, V4-Pro significantly outperforms other open-source models, only slightly trailing behind Google’s Gemini-Pro-3.1.
Agent capabilities have greatly improved. Compared to previous models, DeepSeek-V4-Pro’s agent capabilities have been notably enhanced. In Agentic Coding assessments, V4-Pro has reached the best level among current open-source models and performed excellently in other agent-related evaluations.
Currently, DeepSeek-V4 has become the Agentic Coding model used by the company’s internal employees, with feedback indicating that the user experience surpasses that of Sonnet 4.5, and the delivery quality is close to Opus 4.6 in non-thinking mode, though there remains a gap compared to Opus 4.6 in thinking mode.
DeepSeek-V4’s detailed technical report was also released alongside its launch.

DeepSeek-V4-Flash: A Faster and More Efficient Economic Choice
V4-Flash is positioned as a faster and more economical lightweight option.
Compared to DeepSeek-V4-Pro, DeepSeek-V4-Flash is slightly inferior in world knowledge reserves but demonstrates nearly comparable reasoning abilities.
Due to smaller model parameters and activation scales, its API service offers significant advantages in speed and cost.
In agent assessments, V4-Flash performs comparably to V4-Pro on simple tasks, but still lags behind on more complex tasks.
This positioning makes V4-Flash more suitable for enterprise applications that are sensitive to latency and cost, with moderate task complexity.
Structural Innovation and High Context Efficiency
DeepSeek-V4 introduces a novel attention mechanism at the underlying architecture level.
By compressing on the token dimension and combining it with self-developed DSA sparse attention technology (DeepSeek Sparse Attention), the company claims to have achieved globally leading long-context capabilities while significantly reducing the demand for computational resources and memory compared to traditional methods.
A direct result of this architectural innovation is that a 1M context window will become the standard for all official DeepSeek services.
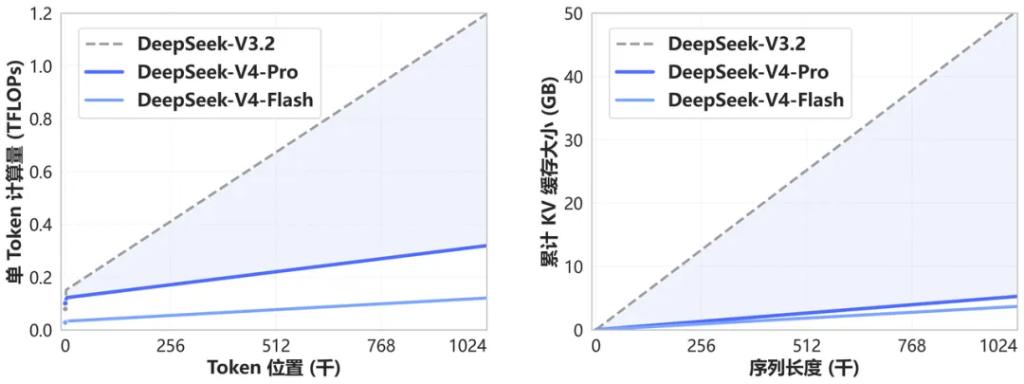
For enterprise users needing to handle long documents, extended dialogues, or complex multi-step tasks, this capability’s availability is of substantial significance.
By reducing computational consumption while expanding the context window, it also helps further lower reasoning costs, reinforcing DeepSeek’s competitive advantage in terms of cost performance.
Agent Ecosystem Adaptation Progressing Simultaneously
DeepSeek stated that the V4 series has been specially adapted and optimized for mainstream agent products such as Claude Code, OpenClaw, OpenCode, and CodeBuddy, resulting in performance improvements in coding tasks and document generation tasks.
At the API level, both models support a maximum context length of 1M and are compatible with both non-thinking and thinking modes.
Thinking mode allows setting reasoning intensity through the reasoning_effort parameter, with options for high or max levels. DeepSeek recommends enabling thinking mode and setting the intensity to max for complex agent scenarios.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.