Claude Opus 4.5 Released: Price Halved, Unlimited Conversations, and Coding Dominance
On November 25, 2025, the AI landscape witnessed a significant shift with the launch of Anthropic’s flagship model, Claude Opus 4.5. This release not only represents a technological iteration but also a market revolution, featuring a staggering two-thirds reduction in API call costs and surpassing all human engineers in rigorous software engineering tests, marking a new era for AI technology.
Top-tier AI Capabilities Enter the Era of Accessibility
Anthropic’s pricing strategy is a game-changer. The input token price for Opus 4.5 has plummeted from $15 per million to just $5, while the output token price has dropped from $75 to $25, achieving an overall reduction of 67%. This pricing level makes many competitors’ mid-tier models look inadequate.
Additionally, Anthropic has announced several accessibility policies: the 32K context window is now completely free, and the previously paid “unlimited conversation” feature is now available to all paying users. This means developers and businesses can now access powerful AI capabilities at a lower cost.
 Scott White, Anthropic’s product lead, stated in a CNBC interview, “We genuinely hope to ensure this technology can truly benefit everyone who wants to use these models. Our core focus has always been: how can Claude better assist you with tasks you might not want to handle personally?”
Scott White, Anthropic’s product lead, stated in a CNBC interview, “We genuinely hope to ensure this technology can truly benefit everyone who wants to use these models. Our core focus has always been: how can Claude better assist you with tasks you might not want to handle personally?”
Coding Ability Surpasses Human Experts for the First Time
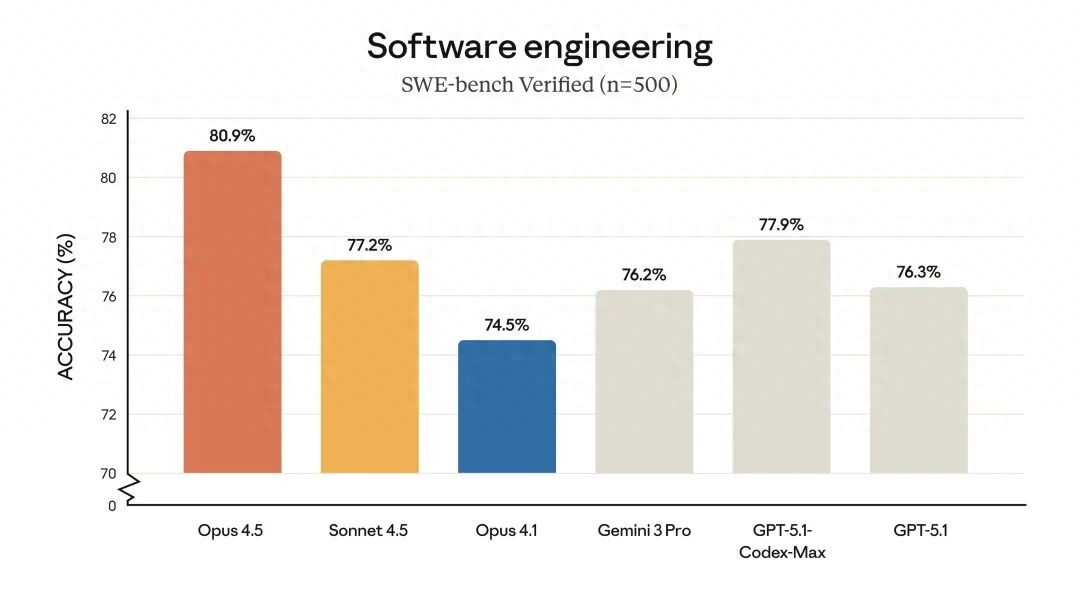
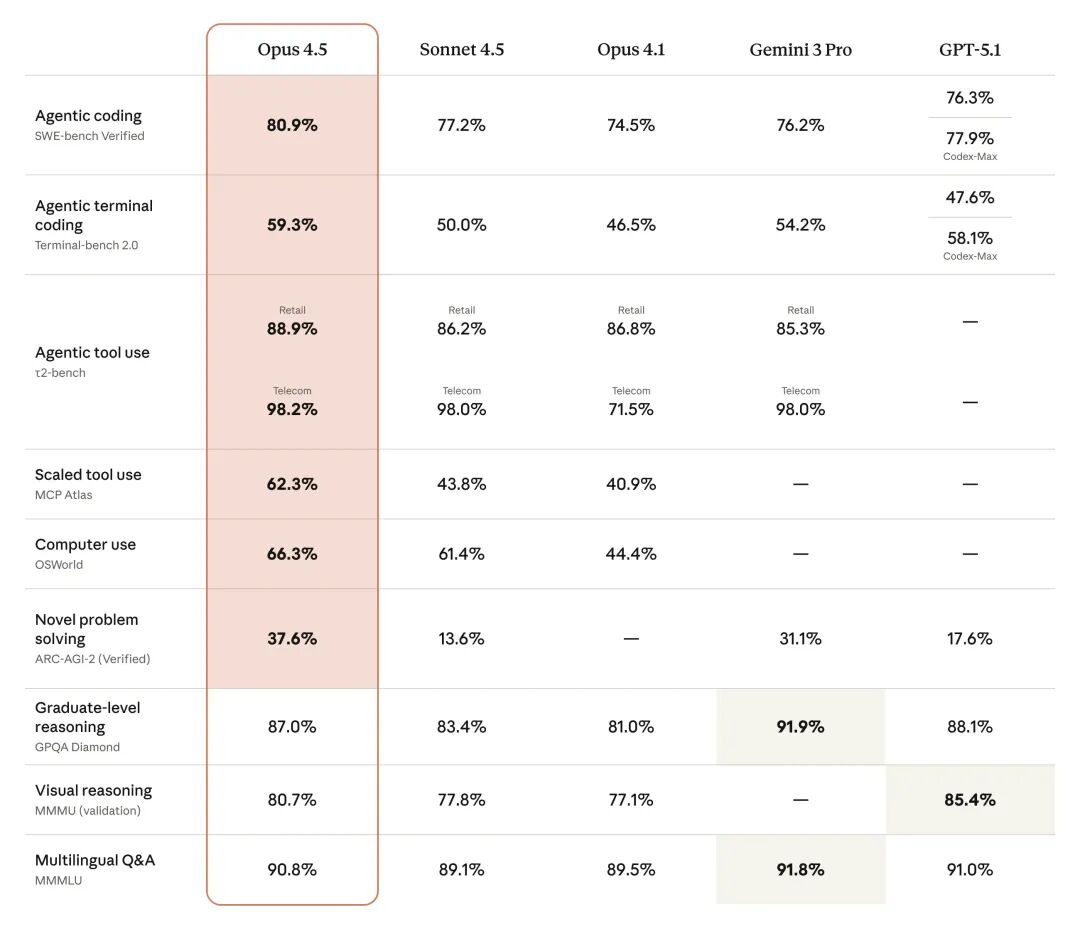
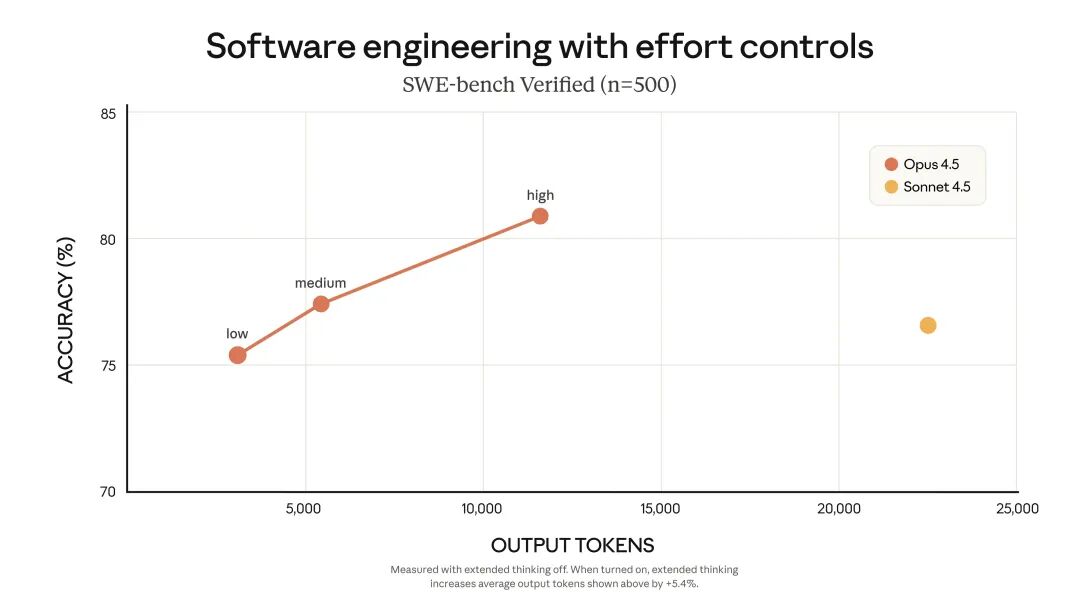
In the authoritative SWE-bench Verified test, Opus 4.5 achieved an astonishing score of 80.9%. This performance not only significantly surpassed OpenAI’s recently released GPT-5.1-Codex-Max (77.9%) and Google’s Gemini 3 Pro (76.2%) but also set a new historical record in Anthropic’s strictest engineering capability tests.
 “Within our designated two-hour limit, Claude Opus 4.5 scored higher than any human candidate,” Anthropic announced on its official blog. This test was originally designed to select top-performing engineers, specifically assessing candidates’ technical skills and professional judgment under time pressure.
“Within our designated two-hour limit, Claude Opus 4.5 scored higher than any human candidate,” Anthropic announced on its official blog. This test was originally designed to select top-performing engineers, specifically assessing candidates’ technical skills and professional judgment under time pressure.
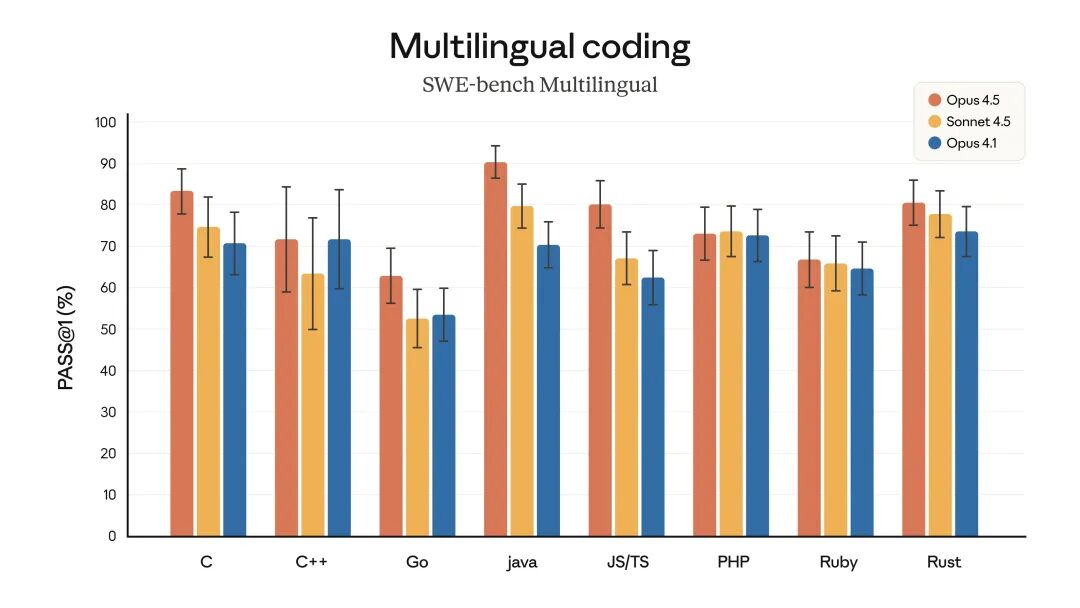 While the company cautiously noted that this test does not measure other critical skills candidates may possess, such as collaboration, communication, or instinct developed over years of experience, this milestone result undoubtedly sparks deep industry reflections on how AI will reshape the engineering technology sector.
While the company cautiously noted that this test does not measure other critical skills candidates may possess, such as collaboration, communication, or instinct developed over years of experience, this milestone result undoubtedly sparks deep industry reflections on how AI will reshape the engineering technology sector.
Perfect Balance of Intelligence and Cost
Opus 4.5 introduces an innovative “effort parameter” mechanism, allowing developers to find the optimal balance between performance and cost. This design reflects Anthropic’s deep understanding of practical application scenarios.
Data shows that at the medium effort level, Opus 4.5 matches Sonnet 4.5’s best performance on SWE-bench Verified while reducing output token usage by 76%. At the high effort level, Opus 4.5 outperforms Sonnet 4.5 by 4.3 percentage points, with token usage still reduced by 48%.
This efficiency improvement has produced significant results in real-world enterprise applications. GitHub’s Chief Product Officer Mario Rodriguez confirmed, “Early tests show that Opus 4.5 excelled in our internal coding benchmarks while halving token usage, making it particularly suitable for complex tasks like code migration and refactoring.”
Replit President Michele Catasta further added, “Opus 4.5 outperformed Sonnet 4.5 and competitors in our internal benchmarks while using fewer tokens to solve the same problems. This efficiency advantage will have a compounding effect in large-scale applications.”
AI Agents Learn to Self-Optimize
Even more astonishingly, Opus 4.5 has demonstrated unprecedented self-optimization capabilities. Tests conducted by Japanese e-commerce giant Rakuten revealed that the AI agent based on Opus 4.5 reached peak performance in just four iterations, while other models could not achieve the same quality even after ten iterations.
Yusuke Kaji, General Manager of Rakuten’s Business AI, stated, “Our agent can autonomously optimize its capabilities—achieving peak performance in four iterations, while other models fail to match this quality even after ten iterations.”
Anthropic’s Albert explained that this ability does not involve the model updating its weight parameters but rather iteratively improving the tools and methods used to solve problems. “It iteratively optimizes a skill within a task, trying to achieve better performance through skill optimization to complete the task.”
This self-evolution capability is not limited to coding tasks. Albert noted that Anthropic has also observed significant improvements in creating professional documents, spreadsheets, and presentations. “Testers told us this is the largest leap they have seen between model generations, even more significant than the progress from Sonnet 4.5 to Opus 4.5 compared to any two consecutive models in the past.”
Comprehensive Workflow Integration Upgrades
Alongside the model’s launch, Anthropic has rolled out significant updates to a suite of productivity tools:
Claude for Chrome is now fully available to all Max users, enabling true cross-browser intelligent operations. Users can seamlessly utilize Claude’s features within browser tabs, greatly enhancing work efficiency.
Claude for Excel has officially launched for Max, Team, and Enterprise users, adding support for advanced features like pivot tables, chart analysis, and file uploads. This means knowledge workers like financial analysts, consultants, and accountants can now handle complex data analysis tasks more efficiently.
Desktop Claude Code now supports parallel running of local and cloud development sessions, providing developers with unprecedented flexibility. Additionally, the newly introduced “programmatic tool invocation” feature allows Claude to directly write and execute code to call functions, significantly expanding its automation capabilities.
Enhanced Enterprise-level Security Capabilities
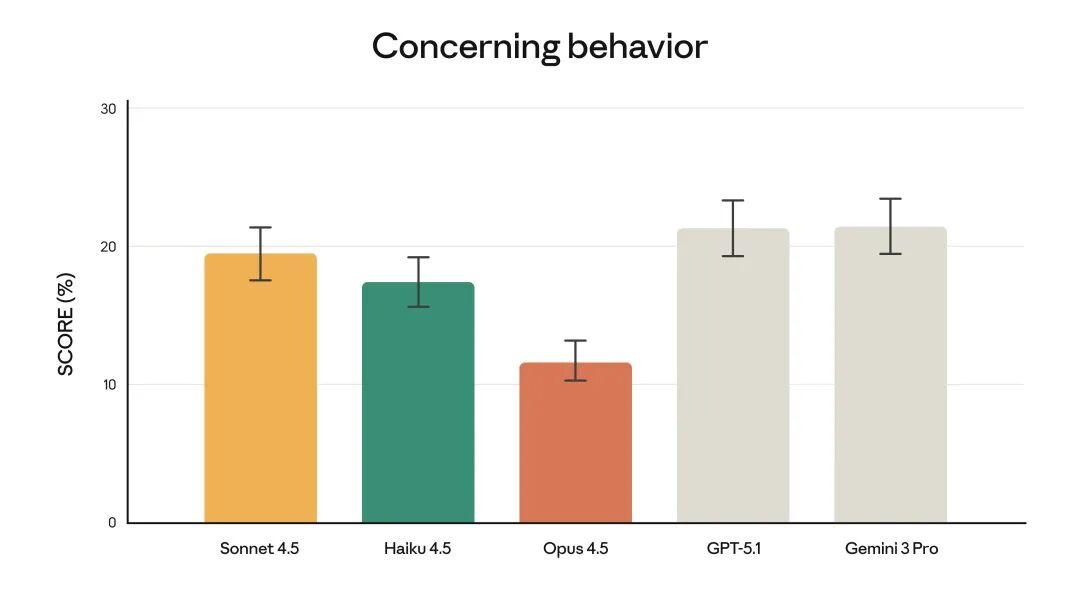
In terms of security performance, Opus 4.5 has shown significant improvements. According to the system card data released by Anthropic, the new model’s robustness against prompt injection attacks has greatly increased:
In a single prompt injection attack test, Opus 4.5’s success rate was only 4.7%, far lower than Gemini 3 Pro’s 12.5% and GPT-5.1’s 12.6%. Even after ten attack attempts, the success rate was controlled at 33.6%, compared to competitors’ 60.7% and 58.2%, showing a marked improvement.
 In agent coding evaluations, Opus 4.5 achieved a 100% rejection rate for 150 malicious coding requests, demonstrating excellent security capabilities. However, when testing scenarios involving malware creation and DDoS attack code writing in the Claude Code environment, the model’s rejection rate was about 78%, while in computer usage scenarios, the rejection rate exceeded 88%, indicating a need for vigilance in specific environments.
In agent coding evaluations, Opus 4.5 achieved a 100% rejection rate for 150 malicious coding requests, demonstrating excellent security capabilities. However, when testing scenarios involving malware creation and DDoS attack code writing in the Claude Code environment, the model’s rejection rate was about 78%, while in computer usage scenarios, the rejection rate exceeded 88%, indicating a need for vigilance in specific environments.
Developer Ecosystem: Laying the Foundation for Next-Gen AI Applications
Anthropic has also made significant upgrades to the Claude developer platform. Enhanced context management and memory features have improved agent task performance by nearly 15%, while new multi-agent coordination capabilities make building complex AI systems more feasible.
 These improvements have already produced significant results in practical applications. Nico Christie, co-founder of financial modeling firm Fundamental Research Labs, reported, “In our internal assessments, accuracy improved by 20%, and efficiency increased by 15%. Tasks that once seemed impossible are now achievable.”
These improvements have already produced significant results in practical applications. Nico Christie, co-founder of financial modeling firm Fundamental Research Labs, reported, “In our internal assessments, accuracy improved by 20%, and efficiency increased by 15%. Tasks that once seemed impossible are now achievable.”
Cursor CEO Michael Truell commented, “Opus 4.5 has shown significant improvements in Cursor compared to previous Claude models, demonstrating better pricing and intelligent performance on difficult coding tasks.” Cognition CEO Scott Wu added, “The model provided stronger results in our toughest evaluations and maintained consistent performance during a 30-minute autonomous coding session.”
Accelerating the Democratization of AI
This release comes at a time when AI competition is reaching a fever pitch—OpenAI just launched the GPT-5.1 series last week, and Google’s Gemini 3 made its debut just seven days ago. Anthropic has completed iterations of three product lines—Haiku, Sonnet, and Opus—in just two months, showcasing remarkable R&D speed and technological accumulation.
Even more impressively, Anthropic achieved an annualized revenue of $2 billion in the first quarter of 2025, doubling from the previous $1 billion. The number of customers spending over $100,000 annually increased eightfold year-on-year, demonstrating the market’s high recognition of its technology.
Albert admitted that this rapid release pace is partly due to using Claude to accelerate its own development. “We have seen many assistive and acceleration effects from Claude in actual product building and model research.”
As AI begins to systematically surpass human experts in professional engineering tests, we stand at a historic turning point. The release of Claude Opus 4.5 not only represents a technological breakthrough but also signals a fundamental change in how we work. This moment marks not just the launch of another AI model but the dawn of a new era in intelligent computing.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.