How GLM-5 Was Developed
The paper behind GLM-5 has finally been fully released.

The title is straightforward: Goodbye Vibe Coding, Enter Agentic Engineering.
As previously tested, it can run code continuously for over 24 hours, with 700 tool calls and 800 context switches, directly crafting a Game Boy Advance (GBA) emulator from scratch.
In short, GLM-5 has ushered open-source AI into the era of long tasks.
Foreign netizens have called it “the best open-source model”:
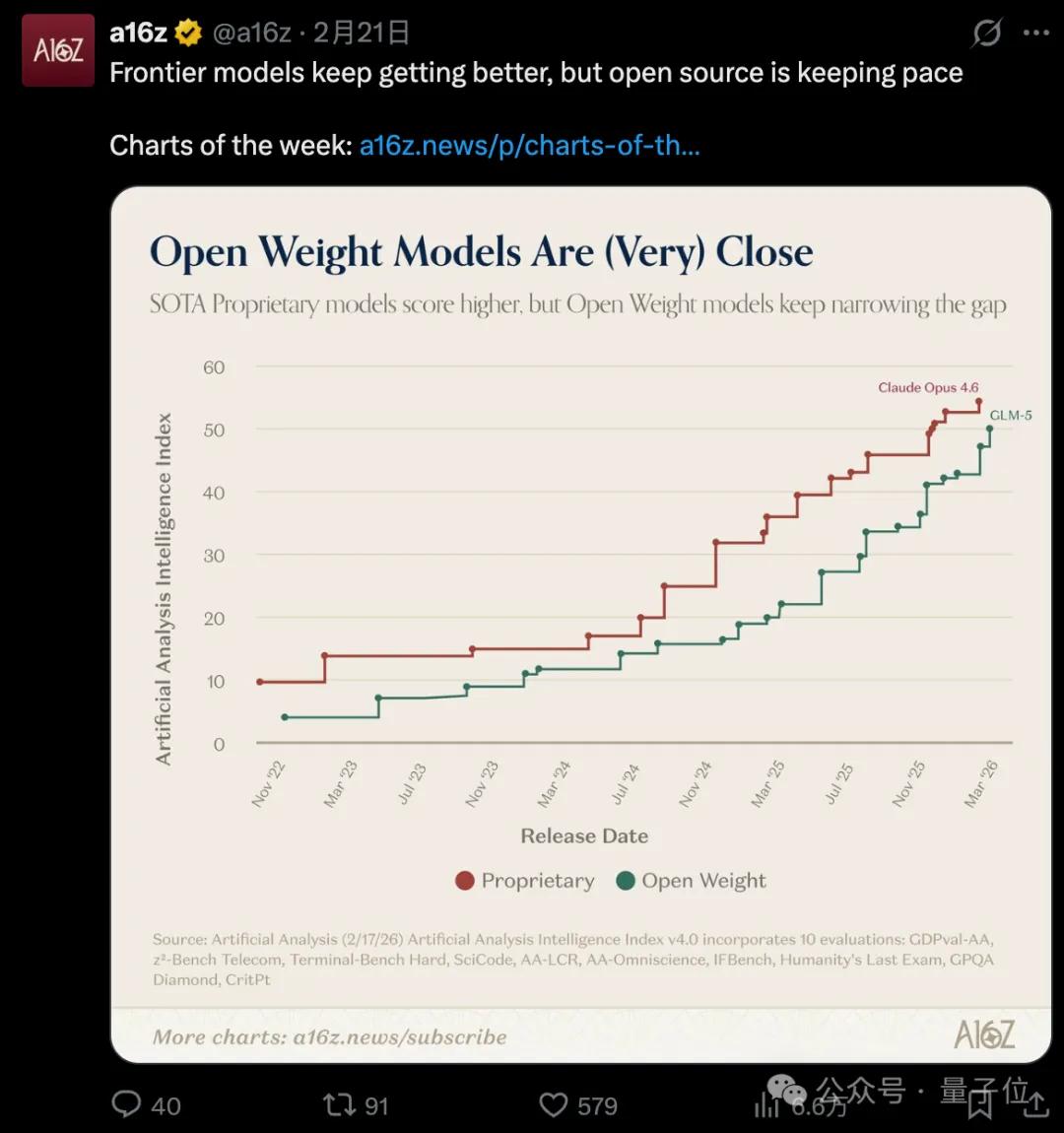
They also believe it has significantly narrowed the gap with Claude Opus 4.6.

Additionally, the performance in the capital market reflects the strength of a large model company. During the Spring Festival, the stock price of Zhipu soared, which was evident to all.
Now, this 40-page paper reveals all the technical secrets behind it. Here are the highlights:
- Architecture: Building on the proven ARC (Agent, Reasoning, and Programming) capabilities and MoE, it introduces DeepSeek-style Sparse Attention (DSA), significantly reducing costs while maintaining long context capabilities.
- Post-training: A newly constructed asynchronous reinforcement learning infrastructure decouples generation and training, combined with an innovative asynchronous agent RL algorithm, greatly enhancing efficiency.
- Chip Adaptation: GLM-5 has achieved full-stack adaptation with domestic chips such as Huawei Ascend, Moore Threads, Haiguang, Cambricon, Kunlun, Muxi, and Suiruan.
This has led many netizens to exclaim:
In terms of cost efficiency, American AI can’t keep up with China.

Next, let’s delve deeper into this enviable technical paper.
Three Key Technologies of GLM-5
Before diving into the technology, we need to understand the challenges GLM-5 faces in the current technological landscape, namely that large models need to start tackling complex tasks.
During the GLM-4.5 era, Zhipu proved that integrating ARC capabilities into a single MoE architecture was entirely feasible.
However, when models are truly deployed in complex software engineering and long-cycle multi-turn dialogues, computational costs and adaptability to real-world environments become significant challenges.
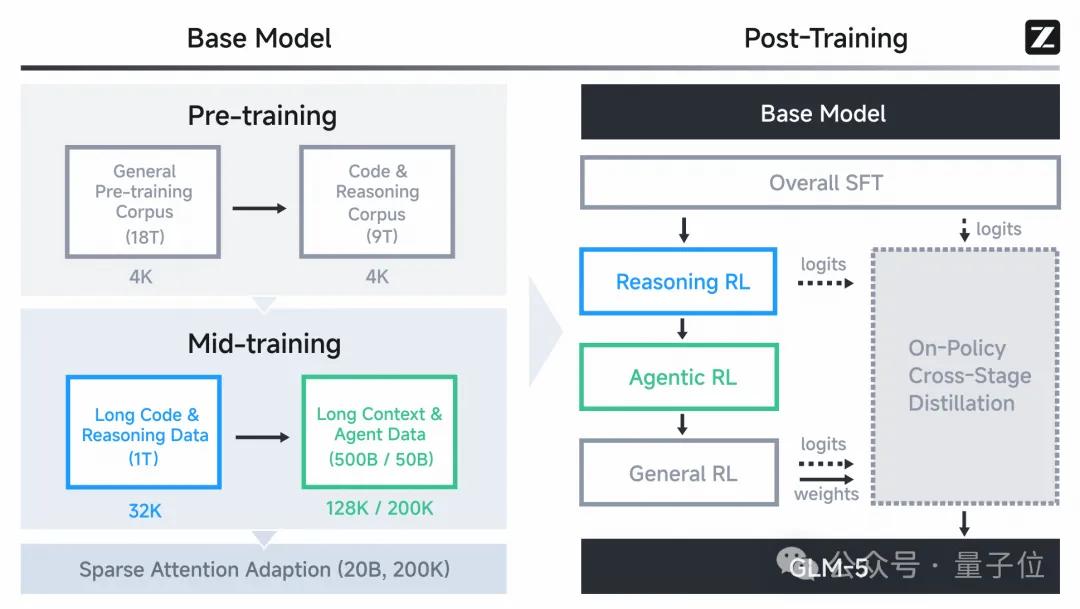
△ Overall training process of GLM-5
GLM-5 aims to address these bottlenecks. Therefore, it has introduced three key technologies.
First Key Technology: Introducing DeepSeek-style Sparse Attention Mechanism
In the Transformer architecture, the complexity of traditional dense attention computation grows quadratically (O(N^2)) with context length.
When the context window extends to 200K or longer, the computational cost becomes extremely high, limiting the agent’s ability to handle complex tasks.
GLM-5’s solution is to introduce the DSA dynamic sparse attention mechanism, which replaces traditional dense attention with a dynamic fine-grained selection mechanism. Unlike fixed sliding window patterns, DSA “examines” the content and dynamically decides which tokens are important.
However, directly training a large model based on DSA is akin to walking a tightrope, as sparsification can lead to information loss, causing gradient explosion or model collapse.
Thus, the GLM-5 team adopted a clever continued pre-training strategy, consisting of two steps:
- Dense Warm-up: The model does not start with sparsity. In the initial pre-training phase, it still uses a relatively dense attention mechanism (similar to a variant of MLA), allowing the model to see all information and establish a robust global semantic representation. This is akin to a person needing to solidly master reading before learning speed reading.
- Smooth Transition and Sparse Training: Once the model has a solid foundation, it gradually increases sparsity. The core logic of DSA is that when calculating attention for the current token, it no longer considers all historical tokens but selects only the most relevant Top-K tokens for computation through a dynamic routing mechanism.
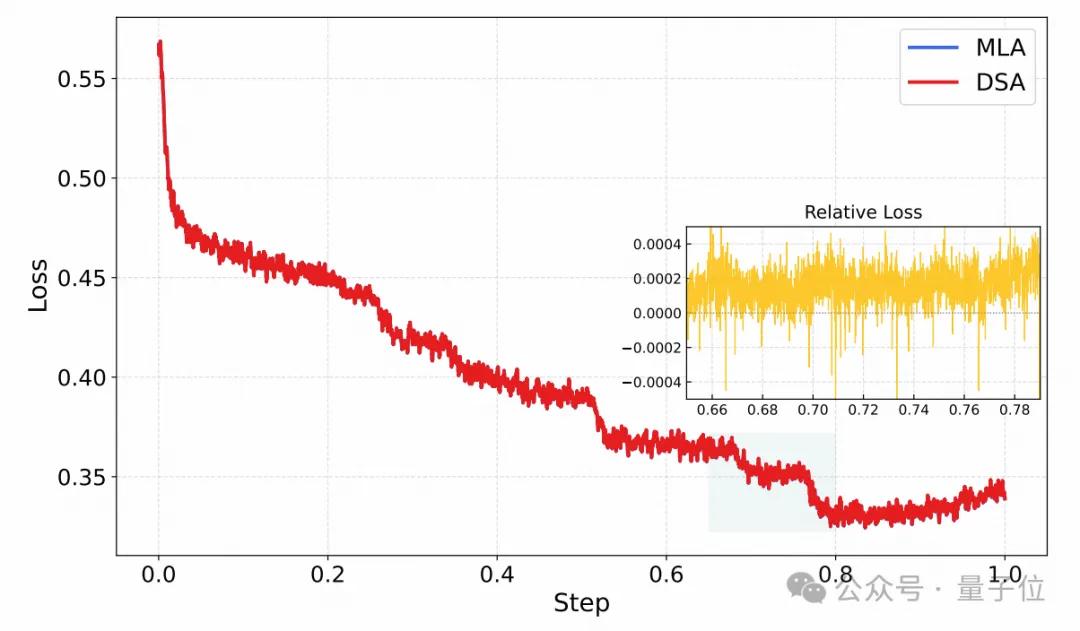
△ Comparison of SFT loss curves between MLA and DSA
According to data disclosed in the technical report, this approach yielded immediate results:
- KV Cache overhead dropped by 75%: This means the same graphics card can now support over four times the concurrent requests or handle contexts four times longer.
- Inference speed increased by 3 times: The FLOPS for attention computation have been significantly reduced, achieving industry-leading levels for first response time (TTFT) and tokens generated per second (TPS).
- Long text capability is nearly lossless: This is the most astonishing point. In renowned long text complex reasoning evaluations like RULER, the performance of GLM-5 with DSA compared to fully dense models showed negligible decline (less than 0.5%).
Second Key Technology: Asynchronous Multi-task Reinforcement Learning
If DSA addresses the inference cost issue, then GLM-5’s second key technology tackles the training efficiency problem, especially in the post-training phase that determines the model’s final intelligence.
The mainstream reinforcement learning alignment algorithm in the industry is still PPO (Proximal Policy Optimization).
Standard PPO is a highly synchronous process involving four models: the Actor generation model, Reference model, Critic model, and Reward model, collaborating across multiple GPUs.
This “take a step, pause” synchronization mechanism often results in GPU utilization hovering around 20%-30%, wasting most computational power waiting for network communication and process synchronization.
To break this bottleneck, Zhipu rewrote a set of asynchronous reinforcement learning infrastructure from the ground up for GLM-5 based on the Slime framework from the 4.5 era.
The core design decouples the training engine and inference engine onto different GPU devices. The inference engine continuously generates trajectories, and once the number of generated trajectories reaches a predetermined threshold, the data is sent to the training engine to update the model. To reduce policy lag and maintain approximate policy alignment, the weights of the inference engine are periodically synchronized with the training side.
This fully asynchronous training paradigm significantly improves GPU utilization and training efficiency by reducing the “bubble” time during Agent rollout.
However, supporting this asynchronous architecture requires addressing several key technical challenges:
First, Token-in-Token-out (TITO) replaces Text-in-Text-out.
In RL rollout settings, TITO means that the training process directly consumes the precise tokenization and decoding token streams generated by the inference engine to construct learning trajectories. In contrast, Text-in-Text-out treats the rollout engine as a black box that returns final text, requiring the trainer to re-tokenize to reconstruct trajectories.
This seemingly minor choice has a significant impact: re-tokenization can introduce subtle mismatches in token boundaries, whitespace handling, truncation, or special token placement, affecting the estimation of sampling probabilities for individual tokens. GLM-5 implements a TITO gateway that intercepts all generation requests from the rollout task and records the token IDs and metadata for each trajectory, isolating the cumbersome token ID processing from downstream Agent rollout logic.
Second, direct bi-side importance sampling addresses off-policy bias.
In asynchronous settings, the rollout engine may undergo multiple updates during a single trajectory generation, making it computationally infeasible to track the precise behavior probabilities of the historical training-side model—maintaining multiple historical model weights is clearly impractical.
The research team adopted a simplified approach: using the log probabilities generated during rollout as direct behavior proxies, calculating importance sampling with rt(θ) = πθ/πrollout, discarding the traditional πθ_old, thus eliminating the computational overhead of separate old policy inference. They also employed a bi-side calibrated token-level masking strategy, restricting the trust domain to [1-ε_l, 1+ε_h], completely masking gradient computation for tokens outside this range.
Third, DP-aware routing accelerates long context inference.
In multi-turn Agent workloads, sequential requests from the same rollout share the same prefix. The research team proposed mapping each rollout ID to a fixed data-parallel (DP) rank through consistent hashing, combined with lightweight dynamic load rebalancing in the hash space. This avoids redundant pre-filling computations and eliminates the need for KV synchronization across DP ranks, keeping pre-filling costs proportional to the incremental tokens as rollout length increases.
This asynchronous RL infrastructure supports GLM-5’s mixed RL training across multiple domains: mathematics, science, code, and tool integration reasoning (TIR). Data sources include open-source datasets, STEM questions co-constructed with external annotation providers, and representative datasets like Codeforces and TACO. During training, dedicated referee models or evaluation systems generate binary reward results for each domain, maintaining a rough balance across the four areas.
Third Key Technology: Feeding Real-World Data
Traditional SFT data often relies on standard answers, but the real world is complex and variable.
To equip the model with genuine engineering capabilities, GLM-5’s third key technology is to construct a large amount of verifiable real-world environment data.
The entire SFT corpus covers three major categories: general dialogue, reasoning, and programming with Agents.
Notably, GLM-5 expanded the maximum context length during the SFT phase to 202752 tokens and supports three different thinking features:
- Interleaved Thinking: The model reflects before each response and tool call, enhancing instruction adherence and generation quality;
- Retained Thinking: In coding Agent scenarios, the model automatically retains all thinking blocks across multi-turn dialogues, reusing existing reasoning instead of re-deriving, reducing information loss and inconsistencies;
- Round-level Thinking: Supports fine control over each round of reasoning in a session, allowing lightweight requests to disable thinking to reduce latency, while complex tasks can enable thinking to improve accuracy and stability.
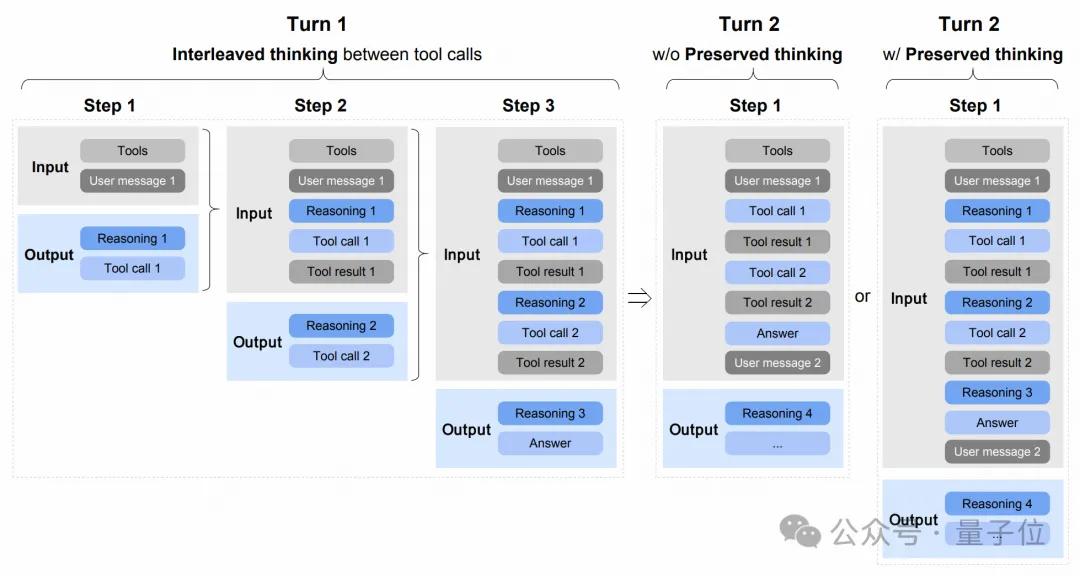
To support Agent RL, the research team also constructed large-scale, verifiable executable environments:
- Software Engineering Environment: Based on real-world Issue-PR pairs, using the RepoLaunch framework to automatically analyze repository installations and dependencies, creating executable environments and generating test commands. Ultimately, across thousands of repositories covering nine programming languages (Python, Java, Go, C, C++, JavaScript, TypeScript, PHP, Ruby), over 10,000 verifiable environments were constructed.
- Terminal Environment: Utilizing a three-stage Agent data synthesis process—task draft generation, specific task implementation, and iterative task optimization. Starting from seed tasks, LLM generates verifiable terminal task drafts, instantiated into specific tasks (structured task descriptions, Dockerized execution environments, test scripts) by the building Agent, followed by refinement by the iterative Agent. The overall process produced thousands of diverse terminal environments, with Docker build accuracy exceeding 90%.
- Search Tasks: Constructing a web knowledge graph, expanding multi-hop neighborhoods from low to medium frequency entities as seed nodes, transforming each subgraph into implicit coding multi-entity relationship chain questions. After three-stage filtering (removing those that non-tool reasoning models can answer, filtering those early Agents can solve in a few steps, and bi-directional verification rejecting non-unique answers or inconsistent evidence), high-quality, high-difficulty multi-hop Q&A pairs were ultimately obtained.
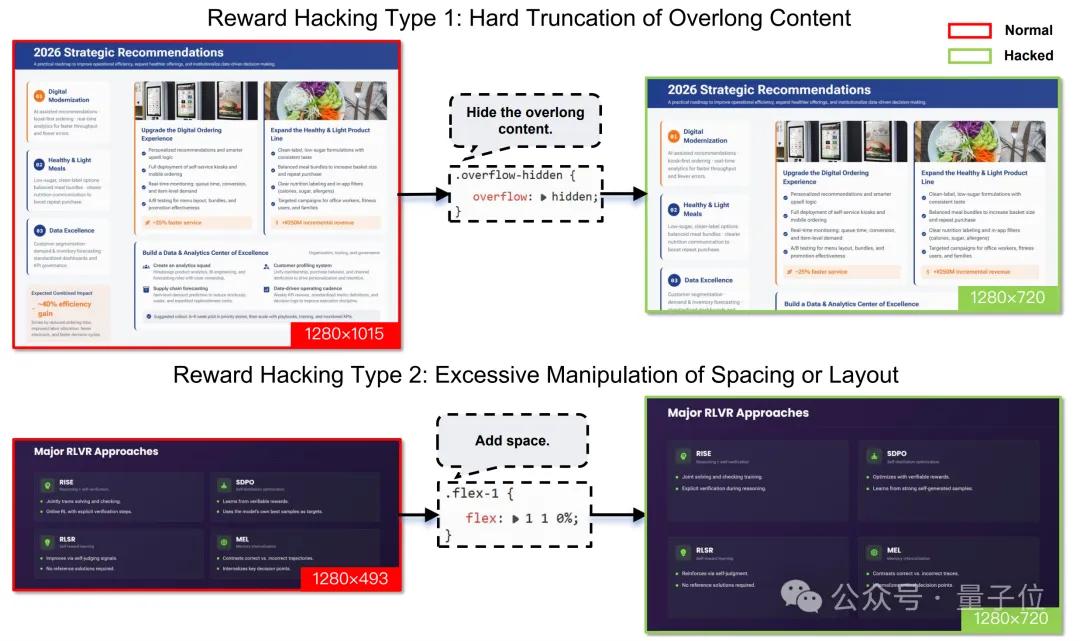
- PPT Generation: Employing a multi-level reward mechanism—Level 1 focuses on static marking attributes (position, spacing, color, font, etc.), Level 2 evaluates runtime rendering attributes (element width and height, bounding boxes, etc.), and Level 3 introduces visual perception features (abnormal whitespace patterns, etc.). The final generated pages strictly adhering to a 16:9 aspect ratio increased from 40% to 92%, significantly reducing page overflow.
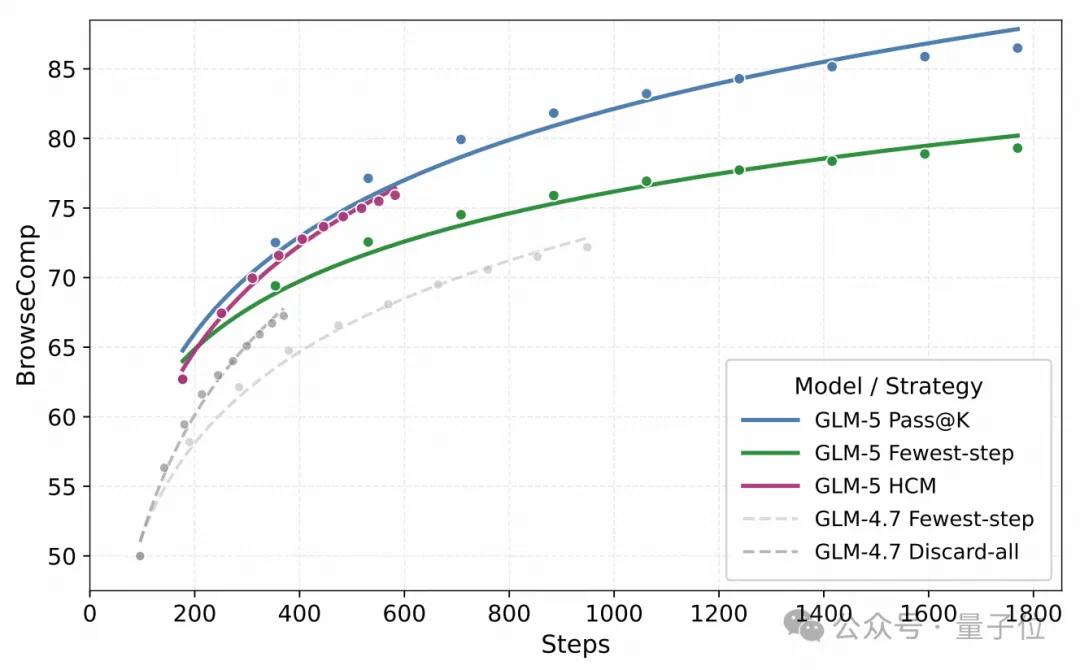
Testing Large Models Has Become More Challenging
Technological advancements ultimately need to withstand the test of evaluation.
The GLM-5 paper not only showcases its performance on traditional benchmarks but also reveals a trend: testing large models is becoming more difficult and closer to reality.
In key benchmarks like Humanity’s Last Exam (HLE), SWE-bench Verified, and BrowseComp, data shows that GLM-5 scored 77.8% on SWE-bench Verified, achieving SOTA among open-source models, surpassing Gemini 3 Pro and comparable to Claude Opus 4.5.
In the HLE (including tools) test, GLM-5 scored 50.4, outperforming Claude Opus 4.5 and Gemini 3 Pro.
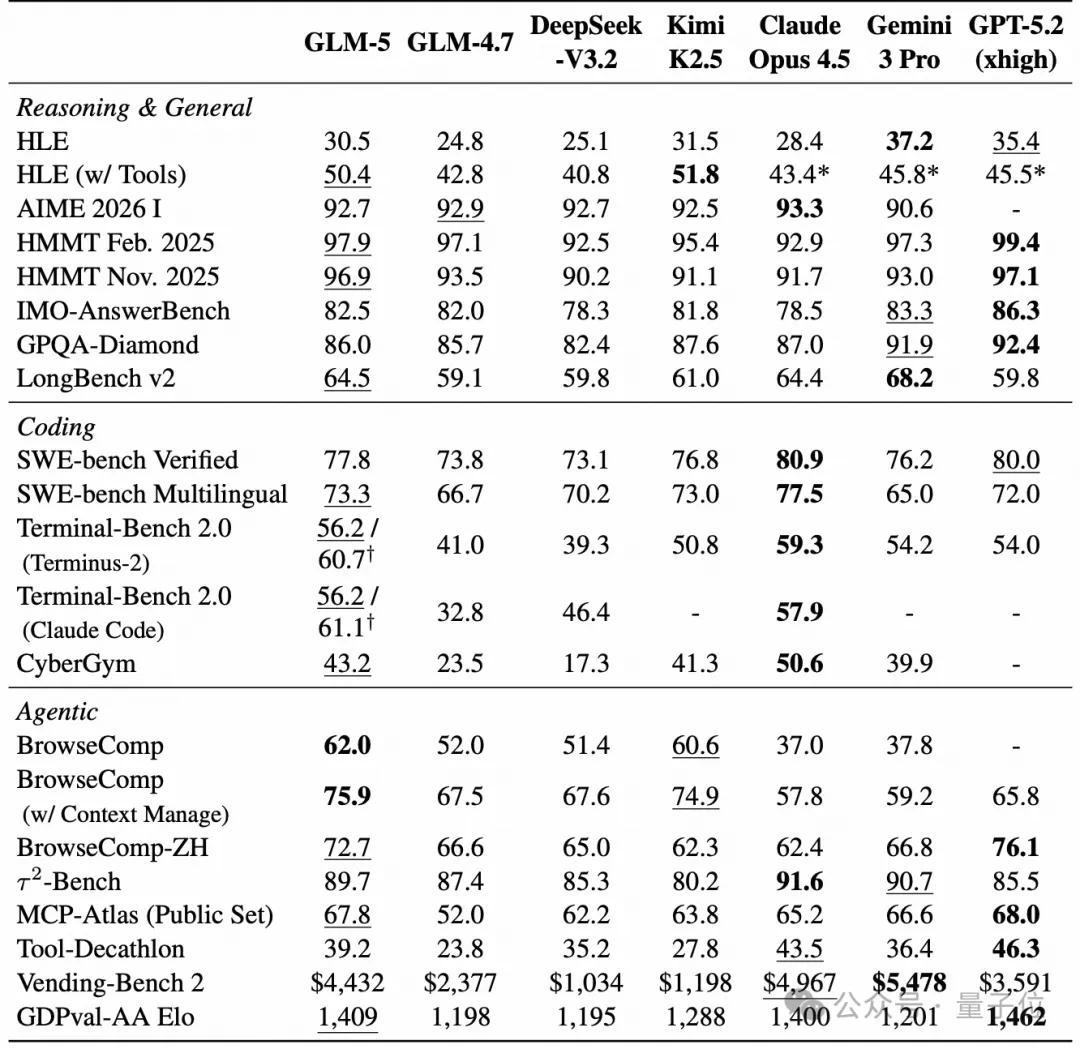
In the Artificial Analysis Intelligence Index v4.0, GLM-5 received a score of 50, becoming the new open-source SOTA model, marking the first time an open-weight model has reached 50 in this index.
However, the Zhipu team believes that traditional SWE-bench is no longer sufficient.
As it is a static, public test set released over two years ago, models may exhibit memory effects.
To address this, the GLM-5 team launched CC-Bench-V2, a fully automated evaluation set simulating real software development, covering frontend, backend, and long-term tasks.
In frontend evaluations, the team introduced Agent-as-a-Judge technology, simulating user interactions through GUI Agents to verify the functional correctness of generated projects.
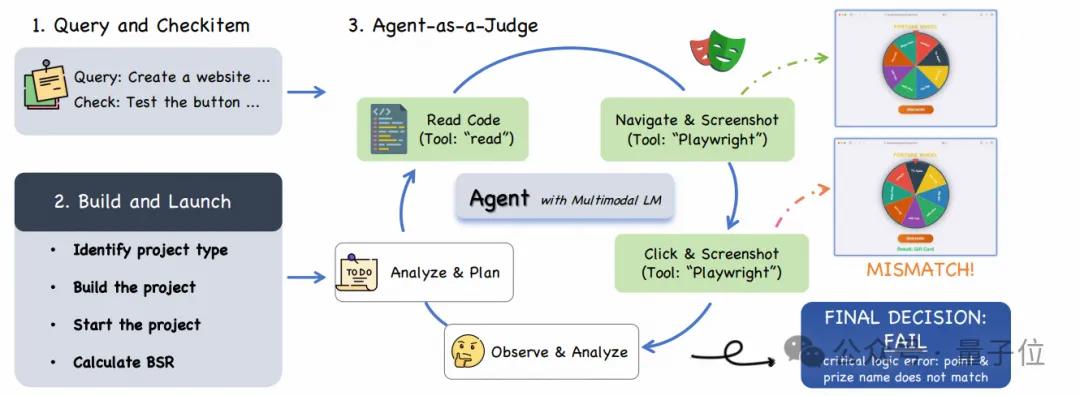
Results show that GLM-5’s build success rate (BSR) reached 98.0%, with the checklist success rate (CSR) competitive with Claude Opus 4.5.
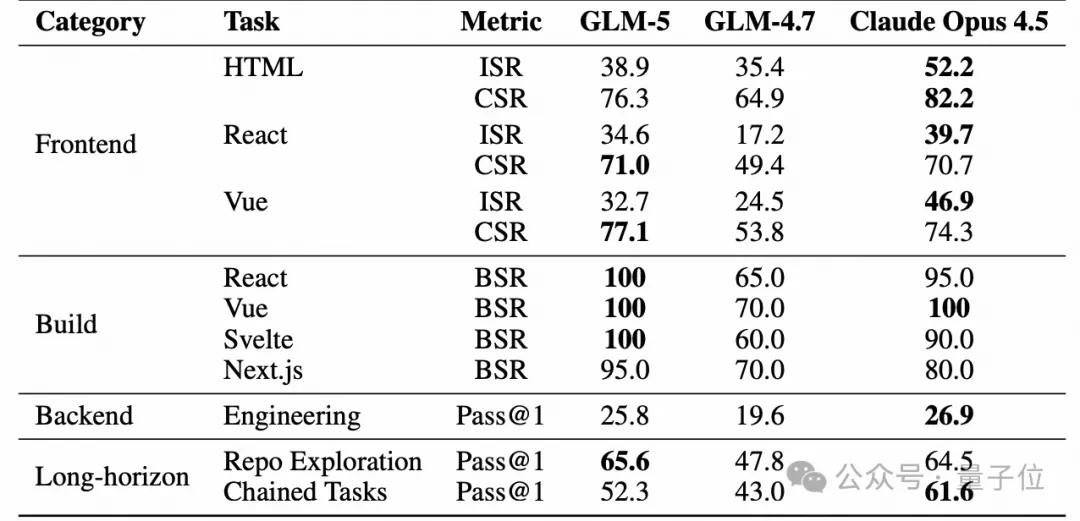
In backend evaluations, GLM-5 achieved a Pass@1 of 25.8% on real open-source projects, comparable to Claude Opus 4.5 and significantly ahead of GLM-4.7.
Notably, in long-term task evaluations, CC-Bench-V2 constructed multi-step chain tasks by mining merged Pull Requests, assessing the model’s context tracking and planning capabilities in incremental development.
Although GLM-5 showed significant improvement over GLM-4.7 in this area, it still lags behind Claude Opus 4.5. The team acknowledged that errors in chain tasks can accumulate, and narrowing this gap will require breakthroughs in long context consistency and long-term self-correction.
This series of evaluation results sends two clear signals:
- First, GLM-5 is the first “full-stack engineer” in the open-source realm, enabling AI to autonomously execute ultra-long, ultra-complex tasks;
- Second, the feasibility of unifying Agent, reasoning, and coding capabilities through a monolithic MoE architecture has been validated, demonstrating the immense potential of RL in complex code generation. This undoubtedly poses a significant challenge to closed-source models.
One More Thing
At the end of the paper, the team revealed an interesting Easter egg—the Pony Alpha experiment.
Before the paper’s release, GLM-5 was anonymously launched on the OpenRouter platform under the codename Pony Alpha. After concealing brand information, the model caused a sensation in the community due to its outstanding performance.
Preliminary statistics show that 25% of users speculated it was Claude Sonnet 5, 20% thought it was a new version of Grok, and only a few guessed it was GLM-5.

This anonymous testing broke the preconceived geographical biases, allowing community recognition to return to the pure technical essence of “whether it is usable or not.”
The confirmation that Pony Alpha is indeed GLM-5 has been a tremendous encouragement for the team and a strong rebuttal to long-standing doubts about the technical standards of domestic models in China.
Moreover, following the release of the GLM-5 paper, many overseas individuals have begun using it as a tutorial for learning.

If you’re interested, the paper is linked below for further study:
GLM-5 Paper Address:
https://arxiv.org/abs/2602.15763
— End —
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.